class: title-slide, inverse .pull-left[ # Applications courantes ## ### Facundo Muñoz<br/>facundo.munoz@cirad.fr<br/>  ] .pull-right[ 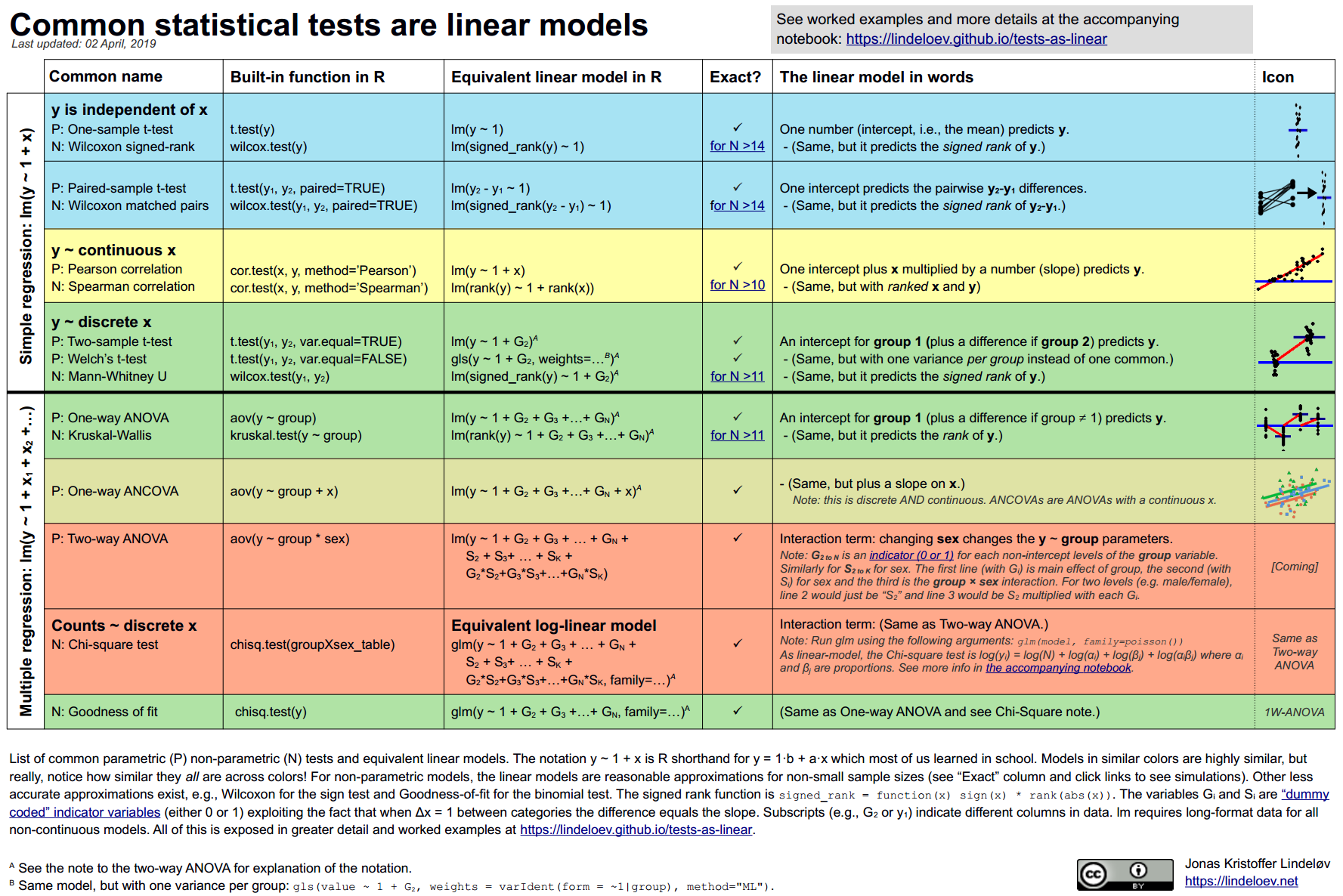 .credit[[Jonas Kristoffer Lindeløv](https://lindeloev.github.io/tests-as-linear/)] ] ??? --- layout: true <a class="footer-link" href="https://umr-astre.pages.mia.inra.fr/training/notions_stats/">Notions de base en statistiques - umr-astre.pages.mia.inra.fr/training/notions_stats/</a> --- class: inverse, middle, center # Tests d'association et indépendance --- # Association linéaire entre variables continues .pull-left[ - __Parenthood__ data - Corrélation empirique : estimateur ponctuel de la __corrélation populationnelle__ - Est-elle __significativement__ différente de 0 ? - Intervalle de confiance ? ] .pull-right[ <img src="S7.1_applications_files/figure-html/unnamed-chunk-1-1.png" width="90%" /> ] ??? Comment de probable il est d'obtenir une telle corrélation ou une autre encore plus forte, si en réalité il n'y avait pas d'association ? --- # Association linéaire entre variables continues .pull-left[ 2 options : 1. Test de corrélation linéaire 2. Modèle linéaire : - force de l'association `\(r^2 = R^2\)` - taille de l'effet (pente) ] .pull-right[  ] ??? La `\(p\)`-valeur du coef. de corrélation est la même que pour le `\(R^2\)` du modèle linéaire (tester association) En revanche, le test pour `\(R\)` dans le modèle linéaire ne donne pas d'intervalle de confiance. Mais souvent ce qui nous intéresse d'avantage c'est la taille de l'effet. Si on normalise les variables, alors `\(\beta = r\)` Résumé : le modèle linéaire apporte des informations plus riches. --- class: inverse, middle, center # Tests de moyennes une ou plusieurs groupes --- # Test _t_ pour la moyenne d'un échantillon .pull-left[ `$$Y \sim \mathcal{N}(\mu,\, \sigma), \, \mathcal{H}_0: \mu = 0$$` - Il y a une valeur de __référence__, à priori - Disons 0. Si non, on soustrait la valeur. - E.g. Différences entre échantillons appariés ] .pull-right[  ] - C'est le __modèle linéaire__ à moyenne constante ! - Test sur l'intercept. ??? Le cas classique est une mesure que se fait __avant__ et __après__ une intervention et on veut évaluer le __changement__. Parfois il y a une valeur de référence de la littérature. Par exemple, pour les heures de sommeil. Dans jamovi, on peut le faire comme modèle linéaire en utilisant une covariable constante qui ne sert à rien. Cependant, il est utile de revenir au modèle Normal comme référence : vous connaissez déjà les hypothèses, etc. --- # Moyennes de deux groupes .pull-left[ Considérons une variable __indicatrice__ `\(\mathbb{I}_1\)` : .small[ <table> <thead> <tr> <th style="text-align:right;"> id </th> <th style="text-align:left;"> gr </th> <th style="text-align:right;"> I1 </th> </tr> </thead> <tbody> <tr> <td style="text-align:right;"> 1 </td> <td style="text-align:left;"> A </td> <td style="text-align:right;"> 0 </td> </tr> <tr> <td style="text-align:right;"> 2 </td> <td style="text-align:left;"> B </td> <td style="text-align:right;"> 1 </td> </tr> <tr> <td style="text-align:right;"> 3 </td> <td style="text-align:left;"> B </td> <td style="text-align:right;"> 1 </td> </tr> <tr> <td style="text-align:right;"> 4 </td> <td style="text-align:left;"> A </td> <td style="text-align:right;"> 0 </td> </tr> </tbody> </table> ] ] .pull-right[ `\(Y \sim \mathcal{N}(\mu_0 + \beta_1 \mathbb{I}_1,\, \sigma)\)` `\(\mathcal{H}_0: \beta_1 = 0\)` .quote[Test _t_ pour échantillons indépendants.] ] - Les hypothèses se dérivent de celles du modèle linéaire : __normalité__, __indépendance__, __homogéneité de variances__ (i.e. la même dans les deux groupes) ??? Le coefficient `\(\beta_1\)` du modèle représente la différence entre les moyennes des deux groupes. --- # Cas pratique .pull-left[ .small[Notes de 33 étudiants par enseignante] .small[ <table> <thead> <tr> <th style="text-align:right;"> ID </th> <th style="text-align:right;"> grade </th> <th style="text-align:left;"> tutor </th> </tr> </thead> <tbody> <tr> <td style="text-align:right;"> 1 </td> <td style="text-align:right;"> 65 </td> <td style="text-align:left;"> Anastasia </td> </tr> <tr> <td style="text-align:right;"> 2 </td> <td style="text-align:right;"> 72 </td> <td style="text-align:left;"> Bernadette </td> </tr> <tr> <td style="text-align:right;"> 3 </td> <td style="text-align:right;"> 66 </td> <td style="text-align:left;"> Bernadette </td> </tr> <tr> <td style="text-align:right;"> 4 </td> <td style="text-align:right;"> 74 </td> <td style="text-align:left;"> Anastasia </td> </tr> <tr> <td style="text-align:right;"> 5 </td> <td style="text-align:right;"> 73 </td> <td style="text-align:left;"> Anastasia </td> </tr> <tr> <td style="text-align:right;"> 6 </td> <td style="text-align:right;"> 71 </td> <td style="text-align:left;"> Bernadette </td> </tr> </tbody> </table> ] .small[Fichier __jamovi__ `Harpo`] ] .pull-right[ __Évidence__ des __grades moyennes différents__ dans les deux sous-groupes ? .small[ 1. Descriptifs et graphiques 2. Comparer la modélisation avec le test _t_ 3. Test de Welch : variances non homogènes ] ] ??? Exercice guidé. 1. Variable `grade` _continue_ 2. Descriptives : grades moyennes et écart-types par tuteur. Histogrammes. 3. Ajuster le modèle linéaire 3. Vérifier la Normalité des résidus avec des Q-Q plots et le test de Shapiro-Wilk et l'homogéneité de variances (residual plot). (Le test de Levene n'es pas disponible ici. Il faut faire le t-test.) 4. Reporter une différence significative. 5. Remarquer la différence d'écart-types entre les groupes et visible dans les résidus. 6. Welch test: variances différentes. Plus dans le cadre du modèle linéaire ! Il faut le faire par le menu (Test t). 6. Test d'homogenéité (Levene) pas significatif !! Ça arrive. Pas bien grave. Et puis, la différence entre `\(p=.43\)` et `\(p=.54\)` n'est pas _significative_ ;) --- # Cas pratique : conclusions .small[ - Les mêmes données peuvent être analysés avec des __modèles alternatifs__ (linéaire, variances hétérogènes, rangs...) - Ce sont des différentes _machines génératrices de données_ qui __reproduisent__ des patterns similaires aux observés - Ses résultats peuvent être en __conflit apparent__ (signif./pas signif.). - Les considérer comme des __éléments de jugement__ et d'aide à la décision. Une quantification de l'__évidence disponible__. - Juger la __pertinence relative__ de chaque modèle dans le contexte de l'étude et les __connaissances préalables__ du chercheur. ] ??? Conflit apparent : les résultats sont en réalité compatibles il y a une légère différence observée entre les groupes, mais c'est difficile, avec ces données de l'attribuer à une différence entre les moyennes où les variances. Si on assume homogénéité de variances, alors il semblerait y avoir une petite différence (significative) de ~5.5 points entre les scores moyennes des 2 groupes. Sinon, le modèle de Welch (équivalent à une extension du modèle linéaire avec une variance par groupe, non disponible en Jamovi) estime la différence à `\(\approx 5.2 = 2 \times SE\)`, où `\(SE \approx 2.6\)` est une erreur standard moyen des groupes. En réalité les 2 résultat sont très semblables, mais par hasard chaque un tombe d'un côté différent du seuil de _significativité_. -- .center[## Les __conclusions__ sont à charge du chercheur] --- # Moyennes de plusieurs groupes .pull-left[ - `drug` : niveau de référence (.placebo[placebo]) + 2 variables indicatrices. `\(Y \sim \mathcal{N}(\mu_0 + \beta_a \mathbb{I}_a + \beta_j \mathbb{I}_j,\, \sigma)\)` - _ANOVA_ d'un facteur (one-way) `\(\mathcal{H}_0: \beta_a = \beta_j = 0\)` ] .pull-right[ <img src="S7.1_applications_files/figure-html/unnamed-chunk-5-1.png" width="90%" /> ] .small[ Le modèle linéaire est plus informatif ! ] ??? Faire les ANOVA et le modèle linéaire sur Jamovi. Seulement avec la variable `drug`. Vérifier la valeur du statistique F pour le `\(R^2\)` (ce celle de l'ANOVA) Comme pour le test `\(t\)`, le modèle linéaire donne bien plus que le test d'égalité de moyennes. --- # Plusieurs variables explicatives .pull-left[ - Dans `Clinical Trial` il y a __2 variables explicatives__ - __Effet de la thérapie__ ? - __Interaction__ entre `drug` et `therapy` ? ] .pull-right[ <img src="S7.1_applications_files/figure-html/unnamed-chunk-6-1.png" width="90%" /> ] ??? Discuter le concept d'__interaction__ Quelqu'un(e) peut l'expliquer ? Seulement 3 observations par groupe ! --- # Toujours un modèle linéaire - `\(3 \times 2\)` groupes - Effets __principaux__ + __interaction__ - En général : `\(Y \sim \mathcal{N}(\mu,\, \sigma)\)` `\(\mu = \mu_0 + \beta_1 X_1 + \beta_2 X_2 + \beta_{12} X_1*X_2\)` - Variables explicatives qualitatives `\(\rightarrow\)` _dummy coding_ ??? Pour chaque variable qualitative `\(X\)` à `\(k\)` niveaux, il en faut `\(k-1\)` variables indicatrices. --- .pull-left[ 1. Modèles __alternatifs__ sans et avec interaction 2. Effets __principaux__ 3. Effets de l'__interaction__ 4. __Comparaison__ de modèles ] .pull-right[  ] - 2-way ANOVA `\(\mathcal{H}_0: \beta_{12}=0\)` (absence d'interaction) (4) ### Le modèle linéaire est beaucoup plus informatif et ça peut nous intéresser utiliser l'interaction, même si pas significative ??? Dans ce cas, il y a très peu de données dans chaque groupe comme pour identifier une interaction significative. Mais il y a des raisons scientifiques pour supçonner que l'effet de la thérapie n'est pas indépendant de l'effet du médicament. Donc, il est plus sage d'utiliser un modèle avec interaction. --- # Récapitulatif .small[ | Objectif | Test classique | Modèle | |------------------------------------------------|----------------------------|-----------------| | Association linéaire entre variables continues | Corrélation de Pearson | `\(Y\sim X\)` | | Test moyenne un groupe | Test _t_ un échantillon | `\(Y\sim 1\)` | | Différence de moyennes 2 groupes indépendants | Test _t_ deux échantillons | `\(Y\sim X\)` | | Différence de moyennes plusieurs groupes | ANOVA d'un facteur | `\(Y\sim X\)` | | Interaction entre facteurs explicatives | ANOVA de deux facteurs | `\(Y\sim X1+X2+X1*X2\)` | ] --- # Conclusions .small[ - Mieux qu'avoir à vous souvenir/rechercher quel test répond à chaque objectif et situation, comment il fonctionne, ses hypothèses, quelle est l'hypothèse nulle, etc., j'ai voulu vous introduire à l'outil fondamental de base : __le modèle linéaire__ - Vous connaissez ses hypothèses : normalité, indépendance de résidus, homogénéité de variances. Elles se déclinent différemment selon la situation. - Vous savez interpréter ses coefficients et en tirer les conclusions pertinentes. - Vous avez beaucoup plus d'information qu'un simple `\(p\)`-valeur (estimation des effets, intervalles de confiance). - Vous réfléchissez sur la pertinence de votre __modèle__ (machine génératrice) et sortez du mode __binaire__ de la [_significantitis_](http://damjan.vukcevic.net/2015/09/21/significantitis/) - Vous pouvez l'utiliser pour d'autres objectifs plus générales et l'étendre dans différentes directions (GLM, LMM, GAM, ...) ] --- class: middle # Merci! Diapositives créées à l'aide du package R [**xaringan**](https://github.com/yihui/xaringan). En s'appuyant sur [remark.js](https://remarkjs.com), [**knitr**](https://yihui.org/knitr), et [R Markdown](https://rmarkdown.rstudio.com). <a rel="license" href="https://creativecommons.org/licenses/by-sa/4.0/deed.fr"><img alt="Licence Creative Commons" style="border-width:0" src="https://i.creativecommons.org/l/by-sa/4.0/88x31.png" /></a><br />Ce(tte) œuvre est mise à disposition selon les termes de la <a rel="license" href="https://creativecommons.org/licenses/by-sa/4.0/deed.fr">Licence Creative Commons Attribution - Partage dans les Mêmes Conditions 4.0 International</a>.