class: title-slide, inverse .pull-left[ # Le modèle linéaire ## ### Facundo Muñoz<br/>facundo.munoz@cirad.fr<br/>  ] .pull-right[ 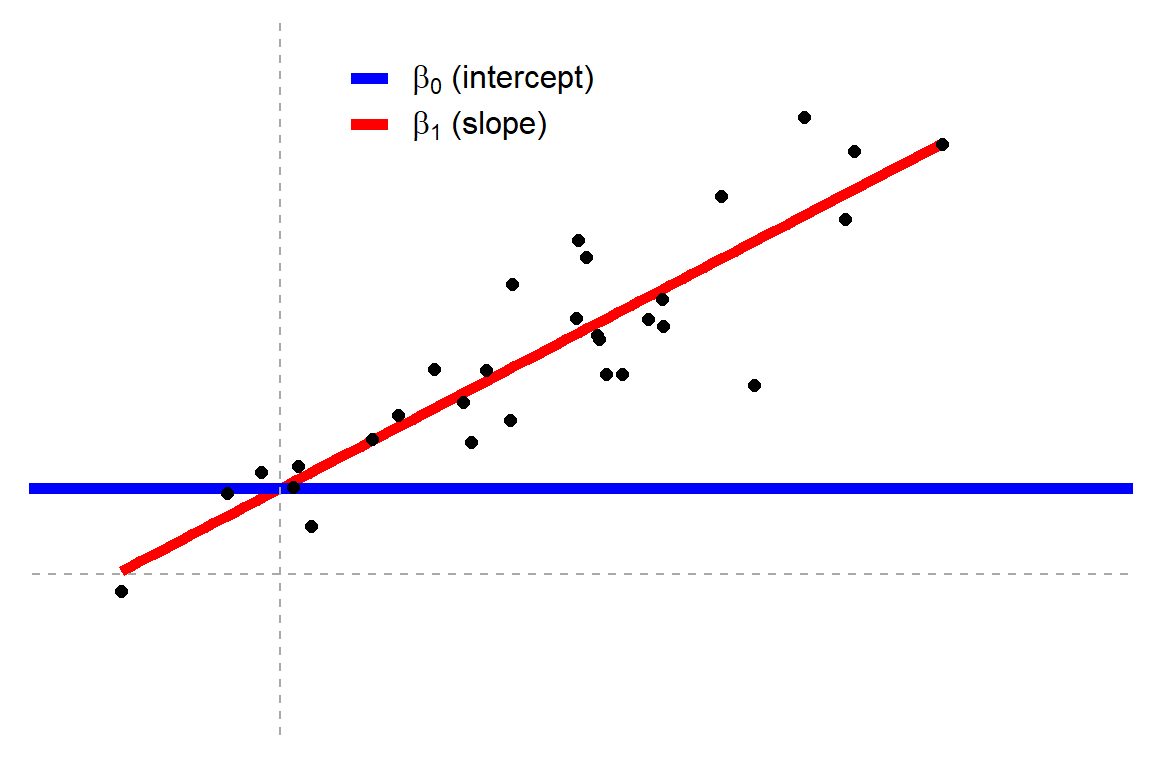 ] ??? --- layout: true <a class="footer-link" href="https://umr-astre.pages.mia.inra.fr/training/notions_stats/">Notions de base en statistiques - umr-astre.pages.mia.inra.fr/training/notions_stats/</a> --- .pull-left[ # Exemple 1 : Clinial Trial Répartition empirique de la variable d'intérêt <img src="S6.2_lm_files/figure-html/clinicaltrial-dotplot-1.png" width="90%" /> ] .pull-right[ .tiny[ <table> <thead> <tr> <th style="text-align:right;"> ID </th> <th style="text-align:left;"> drug </th> <th style="text-align:left;"> therapy </th> <th style="text-align:right;"> mood.gain </th> </tr> </thead> <tbody> <tr> <td style="text-align:right;"> 1 </td> <td style="text-align:left;"> placebo </td> <td style="text-align:left;"> no.therapy </td> <td style="text-align:right;"> 0.5 </td> </tr> <tr> <td style="text-align:right;"> 2 </td> <td style="text-align:left;"> placebo </td> <td style="text-align:left;"> no.therapy </td> <td style="text-align:right;"> 0.3 </td> </tr> <tr> <td style="text-align:right;"> 3 </td> <td style="text-align:left;"> placebo </td> <td style="text-align:left;"> no.therapy </td> <td style="text-align:right;"> 0.1 </td> </tr> <tr> <td style="text-align:right;"> 4 </td> <td style="text-align:left;"> anxifree </td> <td style="text-align:left;"> no.therapy </td> <td style="text-align:right;"> 0.6 </td> </tr> <tr> <td style="text-align:right;"> 5 </td> <td style="text-align:left;"> anxifree </td> <td style="text-align:left;"> no.therapy </td> <td style="text-align:right;"> 0.4 </td> </tr> <tr> <td style="text-align:right;"> 6 </td> <td style="text-align:left;"> anxifree </td> <td style="text-align:left;"> no.therapy </td> <td style="text-align:right;"> 0.2 </td> </tr> <tr> <td style="text-align:right;"> 7 </td> <td style="text-align:left;"> joyzepam </td> <td style="text-align:left;"> no.therapy </td> <td style="text-align:right;"> 1.4 </td> </tr> <tr> <td style="text-align:right;"> 8 </td> <td style="text-align:left;"> joyzepam </td> <td style="text-align:left;"> no.therapy </td> <td style="text-align:right;"> 1.7 </td> </tr> <tr> <td style="text-align:right;"> 9 </td> <td style="text-align:left;"> joyzepam </td> <td style="text-align:left;"> no.therapy </td> <td style="text-align:right;"> 1.3 </td> </tr> <tr> <td style="text-align:right;"> 10 </td> <td style="text-align:left;"> placebo </td> <td style="text-align:left;"> CBT </td> <td style="text-align:right;"> 0.6 </td> </tr> <tr> <td style="text-align:right;"> 11 </td> <td style="text-align:left;"> placebo </td> <td style="text-align:left;"> CBT </td> <td style="text-align:right;"> 0.9 </td> </tr> <tr> <td style="text-align:right;"> 12 </td> <td style="text-align:left;"> placebo </td> <td style="text-align:left;"> CBT </td> <td style="text-align:right;"> 0.3 </td> </tr> <tr> <td style="text-align:right;"> 13 </td> <td style="text-align:left;"> anxifree </td> <td style="text-align:left;"> CBT </td> <td style="text-align:right;"> 1.1 </td> </tr> <tr> <td style="text-align:right;"> 14 </td> <td style="text-align:left;"> anxifree </td> <td style="text-align:left;"> CBT </td> <td style="text-align:right;"> 0.8 </td> </tr> <tr> <td style="text-align:right;"> 15 </td> <td style="text-align:left;"> anxifree </td> <td style="text-align:left;"> CBT </td> <td style="text-align:right;"> 1.2 </td> </tr> <tr> <td style="text-align:right;"> 16 </td> <td style="text-align:left;"> joyzepam </td> <td style="text-align:left;"> CBT </td> <td style="text-align:right;"> 1.8 </td> </tr> <tr> <td style="text-align:right;"> 17 </td> <td style="text-align:left;"> joyzepam </td> <td style="text-align:left;"> CBT </td> <td style="text-align:right;"> 1.3 </td> </tr> <tr> <td style="text-align:right;"> 18 </td> <td style="text-align:left;"> joyzepam </td> <td style="text-align:left;"> CBT </td> <td style="text-align:right;"> 1.4 </td> </tr> </tbody> </table> ] ] ??? On reprend le cas du Clinical Trial comme motivation Rappelons que un psychologue évalue l’humeur de chaque personne après trois mois de traitement avec chaque drogue, et l’amélioration globale de l’humeur de chaque personne est évaluée sur une échelle allant de -5 à +5. --- .pull-left[ # Exemple 1 : Clinial Trial Répartition empirique de la variable d'intérêt ] .pull-right[ - Pour l'instant, nous avons juste le __modèle Normal__ dans notre boîte à outils .tiny[_Le gain d'humeur se distribue aléatoirement autour d'une valeur moyenne, avec une certaine dispersion Gaussienne_] <img src="S6.2_lm_files/figure-html/normal-model-1.png" width="90%" /> - En principe, compatible avec les observations ] ??? En particulier, ce modèle assume implicitement que le résultat est indépendant du traitement pris. --- .pull-left[ # Exemple 1 : Clinial Trial L'objectif de l'étude est de quantifier l'influence d'une __variable explicative__ `mood.gain` `\(\leftarrow\)` `drug` <img src="S6.2_lm_files/figure-html/clinicaltrial-grouped-dotplot-1.png" width="90%" /> ] ??? Nous avons de bonnes raisonnes pour penser que ce n'est pas le cas. - Déjà, les traitements on été conçus pour __provoquer un effet__. - La visualisation des données suggère que c'est le cas D'ailleurs, on veut __évaluer__ et __quantifier__ cet effet. Nous avons besoin d'un modèle qui admette cette possibilité. __Quelle modification du modèle proposeriez-vous ?__ -- .pull-right[ - Considérons un __modèle Normal__ dont la __moyenne dépend du traitement__ <img src="S6.2_lm_files/figure-html/anova-clinicaltrial-1.png" width="90%" /> - __4 paramètres__ (écart type `\(\sigma\)` __commun__) ] --- # _Dummy coding_ Afin de modéliser une __moyenne différente__ pour chaque groupe nous (le logiciel) allons nous servir de deux variables __binaires__ auxiliaires. .pull-left[ | | `\(\mathbb{I_a}\)` | `\(\mathbb{I_j}\)` | `\(\mu\)` | |---------------------|-------|-------|-------------------| | .placebo[placebo] | 0 | 0 | `\(\mu_0\)` | | .anxifree[anxifree] | 1 | 0 | `\(\mu_0 + \beta_a\)` | | .joyzepam[joyzepam] | 0 | 1 | `\(\mu_0 + \beta_j\)` | ] .pull-right[ .small[La moyenne du modèle est définie comme une __fonction linéaire__ de deux variables __indicatrices__:] `$$\mu(\mathbb{I}_a, \mathbb{I}_j) = \mu_0 + \beta_a \mathbb{I}_a + \beta_j \mathbb{I}_j$$` ] --- # Le modèle linéare : un modèle Normal à moyenne variable `$$Y \sim \mathcal{N}(\mu_0 + \beta_a \mathbb{I}_a + \beta_j \mathbb{I}_j,\, \sigma)$$` .pull-left[ - `\(Y\)` est la variable réponse `mood.gain` - `\(\mathbb{I}_a\)` et `\(\mathbb{I}_j\)` sont variables __indicatrices__ des groupes .anxifree[anxifree] et .joyzepam[joyzepam] Valent __1__ si l'observation est dans le groupe et __0__ si non. ] .pull-right[ 3 modèles Normales différentes selon le groupe : .small[ - .placebo[placebo] `\(Y \sim \mathcal{N}(\mu_0,\, \sigma)\)` - .anxifree[anxifree] `\(Y \sim \mathcal{N}(\mu_0 + \beta_a,\, \sigma)\)` - .joyzepam[joyzepam] `\(Y \sim \mathcal{N}(\mu_0 + \beta_j,\, \sigma)\)` ] ] ??? --- # Le modèle linéare : coefficients `$$Y \sim \mathcal{N}(\mu_0 + \beta_a \mathbb{I}_a + \beta_j \mathbb{I}_j,\, \sigma)$$` .pull-left[ - `\(\mu_0 = \mu_0\)` - `\(\beta_a = \mu_1 - \mu_0\)` - `\(\beta_j = \mu_2 - \mu_0\)` ] .pull-right[ <img src="S6.2_lm_files/figure-html/anova-clinicaltrial-1.png" width="90%" /> .small[ ❗ `\(\sigma\)` est __homogène__ sur les 3 groupes] ] - Numériquement plus stable - __Éficacité__ du traitement : `\(\beta_j = 0\)` ? ??? Jamovi et la plus part des logiciels statistiques font cette réparamétrisation à votre place. Mais il faut savoir qu'elle se fait pour interpréter les résultats correctement. --- background-image: url(img/clinicaltrial-lm1.png) background-position: center background-size: contain --- # Notes pratiques - Le coefficient `\(\mu_0\)` de référence s'appelle __Intercept__ - Les variables indicatrices (_dummy_) se calculent __automatiquement__. - Mais il faut les comprendre pour __interpréter__ les estimations correctement - Vous vous limitez à identifier les __variables__ réponse et explicatives, selon son type (quantitatives ou qualitatives) - Vous pouvez changer le groupe (niveau) de __référence__ ??? L'équation pour la moyenne du modèle a une structure __linéaire__ L'_intercept_ est la valeur de la moyenne quand "X" (toutes les variables) valent 0 (ce qui ici, correspond à la moyenne du groupe placebo) --- # Interprétation des résultats - Résultat principal : __estimation ponctuelle__ des paramètres - `\(\hat\mu_0 = 0.450\)` (moyenne groupe .placebo[placebo]) - `\(\hat\beta_a = 0.267\)` (.anxifree[anxifree] - .placebo[placebo]) - `\(\hat\beta_j = 1.033\)` (.joyzepam[joyzepam] - .placebo[placebo]) - Ces valeurs sont ceux qui mieux __s'ajustent__ aux données observées - Si on répétait l'expérience on obtiendrait d'autres certainement __différents__ ! ??? L'estimation de l'écart type `\(\sigma\)` ne s'affiche pas par défaut car elle n'est pas normalement une quantité d'intérêt. On peut demander un ANOVA test et faire la racine de la variance résiduelle estimée (Mean Square). --- # Evaluation de l'ajustement du modèle .pull-left[ `$$Y \sim \mathcal{N}(\mu_0,\, \sigma)$$` <img src="S6.2_lm_files/figure-html/clinicaltrial-normal-model-1.png" width="90%" /> .small[ Modèle __vide__. Sans variables _explicatives_. Pure variation aléatoire. ] __Variation totale__ ] .pull-right[ `$$Y \sim \mathcal{N}(\mu_0 + \beta_a \mathbb{I}_a + \beta_j \mathbb{I}_j,\, \sigma_0)$$` <img src="S6.2_lm_files/figure-html/unnamed-chunk-2-1.png" width="90%" /> Variation __résiduelle__ `\(\sigma\)` réduite. Une partie de la variation a été __expliquée__. ] ??? Le modèle vide sert de référence. De zéro. --- # Proportion de la variation expliquée a.k.a Le _coéfficient de détermination_ `\(R^2 \in (0, 1)\)` .pull-left[ - `SS` : sommes de carrés des résidus - S'il n'y avait pas de différence entre les groupes `\(\rightarrow \beta_a \approx 0, \, \beta_j \approx 0\)` et `\(R^2 \approx 0\)` ] .pull-right[ `$$R^2 = \frac{SS_{\text{Total}} - SS_{\text{Error}}}{SS_{\text{Total}}}$$` 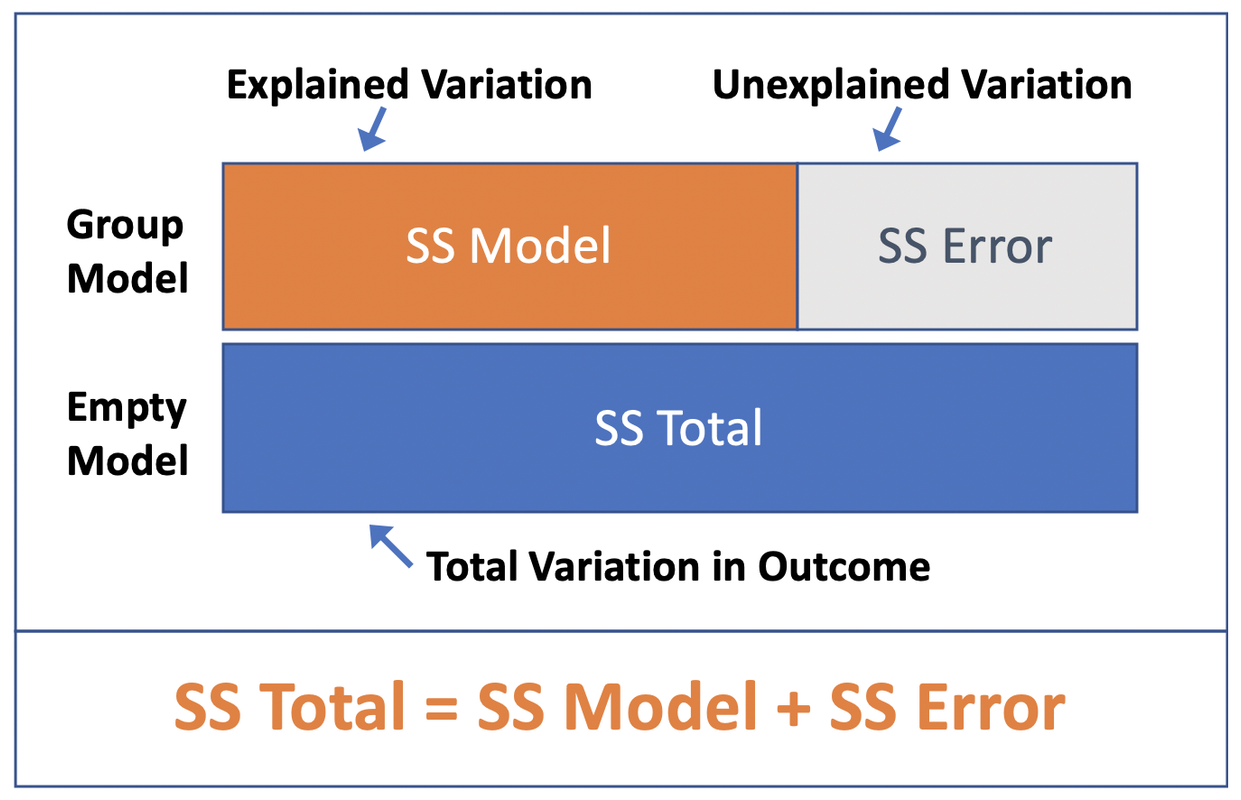 ] ??? Les sommes de carrés est liée à la variance et est utilisée grâce à cette propriété de composition. C'est une technicité pas importante du tout. Allez voir dans jamovi la proportion de variabilité expliquée par le nouveau modèle. Il y a aussi une valeur `\(R^2\)` ajustée, qui introduit une correction du fait que l'introduction de nouvelles variables entraînent toujours une augmentation du `\(R^2\)`, même par pure chance. Par contre, le coefficient ajusté n'a pas d'interprétation simple. --- class: inverse, middle, center # Incertitude dans les estimations ??? Nous avons obtenu des __estimations__ des coefficients et de la proportion de variance expliquée par le modèle. Ce sont des __estimations__ alors forcement pas exactes. C'est le meilleur qu'on peut dire avec les données qu'on a et en supposant que le modèle est correct. Nous devons donner une mesure de la précision de ces estimations. Ce n'est pas la même chose d'estimer les paramètres avec 18 observations qu'avec 180 !! --- # Intervalles de confiance sur les coefficients .pull-left[ - Fourchettes de valeurs __plausibles__ pour les coefficients - Est 0 dans l'intervalle ? (test associée) - L'effet du .joyzepam[joyzepam] est __significativement__ différent de 0 ] .pull-right[  ] --- # Interprétation .pull-left[ - L'effet __non significatif__ d'.anxifree[anxifree], signifie-t-il que ce médicament n'a __aucun effet__ ? __NON__. Ça veut dire que on n'a __pas suffisamment d'éléments__ pour exclure cette possibilité. Si l'effet était nul, la différence observée ne serait pas trop improbable. ] -- .pull-right[ - L'effet __significatif__ de .joyzepam[joyzepam] démontre son __efficacité__ ? __NON__. Ça veut dire que l'évidence disponible __suggère__ que son effet n'est pas nul. L'effet peut être __minuscule__ et irrelévant cliniquement et être quand même statistiquement _significatif_. ] ??? On creusera sur l'interprétation des IC et de tests demain. <!-- --- --> <!-- - Estimations de coefficients `\(\beta\)` : --> <!-- - Intervalles de confiance --> <!-- - Test d'hypothèse `\(\mathcal{H}_0: \beta = 0\)` --> <!-- - Proportion de variabilité expliquée --> <!-- - Test d'hypothèse `\(\mathcal{H}_0: R^2 = 0\)` --> <!-- L'interprétation de ces quantités n'est pas évidente, ni intuitive, mais donnent une mesure de la résolution d'estimation des données observées. --> --- # Covariables continues `$$Y \sim \mathcal{N}(\mu_0 + \beta X,\, \sigma)$$` .pull-left[ - Observations pas réparties en groupes discrètes, mais le long d'une __variable continue__ `\(X\)` - La moyenne augmente ou diminue à un rythme constant `\(\beta\)` - `\(\mu_0 + \beta X\)` : la _droite de regréssion_ ] .pull-right[ 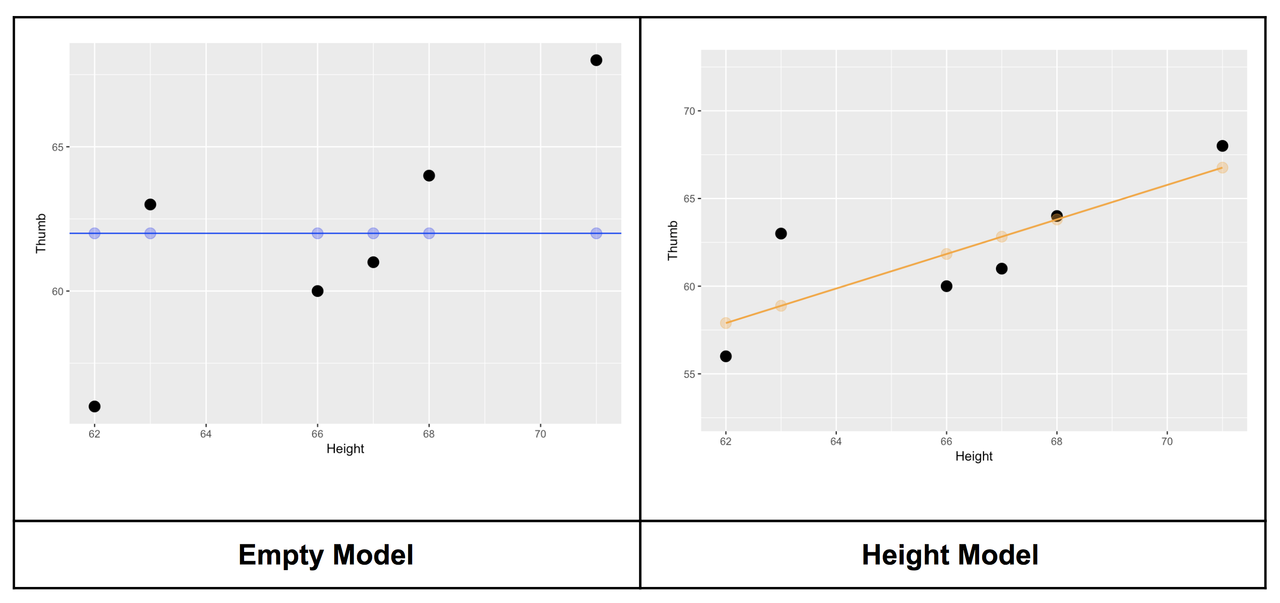 ] --- # Hypothèses du modèle linéaire Le modèle assume implicitement : .pull-left[ 1. Normalité 2. indépendance 3. homogéneité de variances ] .pull-right[ 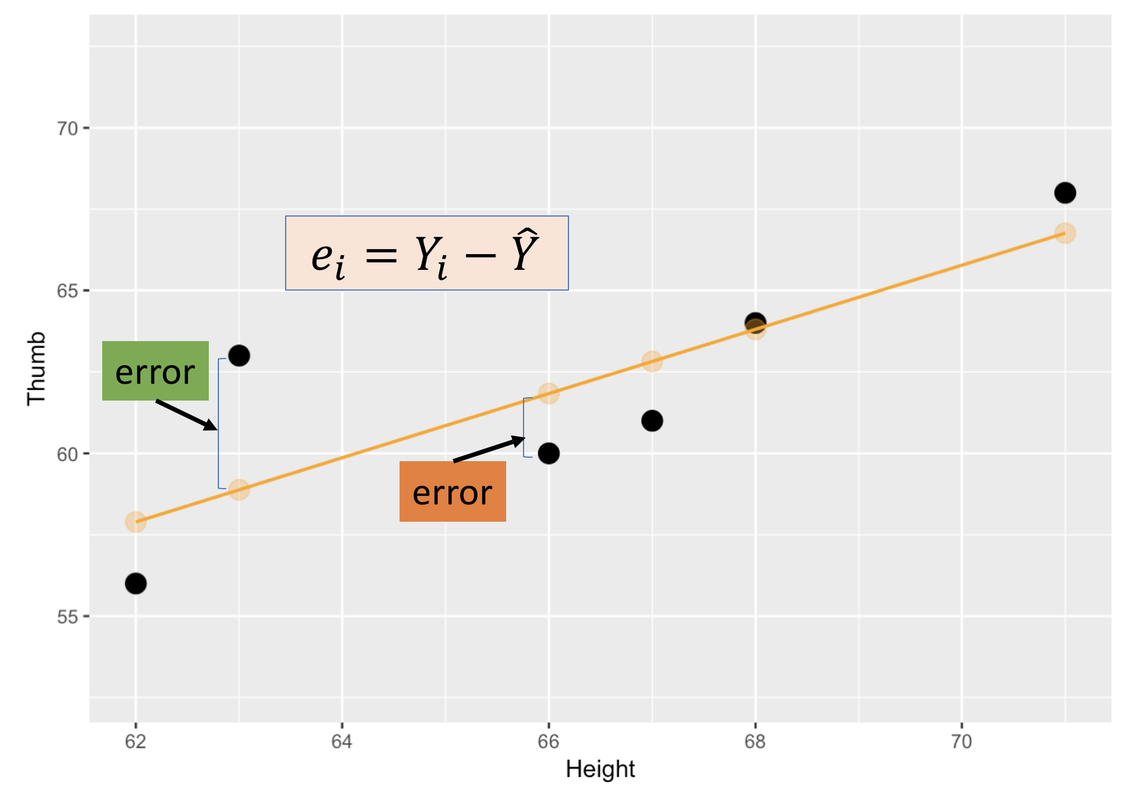 ] Conditions à vérifier à l'aide de graphiques et tests diagnostiques suite à l'ajustement. ??? Ces conditions doivent se vérifier à l'aide de plusieurs graphiques diagnostiques suite à l'ajustement d'un modèle. Pas besoin de perfection, juste d'éviter des grosses déviations de ces hypothèses. --- # Cas pratique .pull-left[  .small[Fichier __jamovi__ `Parenthood`] ] .pull-right[ Quel est __l'effet du sommeil du bébé__ sur l'humeur du père ? .small[ 1. Descriptifs et graphiques 2. Quelles variables sont pertinentes ? 3. Comparer différents modèles possibles (test F, AIC, BIC) 4. Discuter et interpréter les résultats ] ] ??? Exercice guidé. 1. Évidemment, `dan.grump ~ baby.sleep` pour commencer 2. Ajouter `dan.sleep` ? Noter que dans ce cas, l'effet du `baby.sleep` s'annule. Pour quoi ? 3. D'ailleurs le modèle est beaucoup mieux. Quel est l'effet du sommeil du bébé alors ? --- # Conclusions - Selon le type et caractéristiques des variables, plusieurs tests peuvent se formuler en termes d'un __modèle linéaire__. [Common statistical tests are linear models ](https://lindeloev.github.io/tests-as-linear/#52_welch%E2%80%99s_t-test) - Le choix des variables pertinentes dépend de l'__objectif__ de recherche (e.g. prédiction vs estimation). - L'effet (et la significativité) des variables dépend aussi des __autres__ variables présentes. ??? C'est ce qu'on va aborder la séquence suivante --- # Récapitulatif de conceptes .pull-left[ - Modèle Normal à __moyenne variable__ - Modèle __linéaire__ : covariables quantitatives ou qualitatives - Variables __indicatrices__ pour codification des __facteurs__ - Interprétation de __coefficients de contraste__ - __Niveau de référence__ d'un facteur ] -- .pull-right[ - __Estimateurs ponctuels__ des paramètres - Variation __résiduelle__, __totale__ et __expliquée__ - __Proportion de variation expliquée__ (Coef. `\(R^2\)`) - __Intervalles de confiance__ et tests d'hypothèse sur les coefficients - __Signification statistique__ ] ??? Demander aux participants qu'expliquent chaque un un de ces concepts avec ses propres mots. --- class: middle, center # Bravo !  --- class: middle # Merci! Diapositives créées à l'aide du package R [**xaringan**](https://github.com/yihui/xaringan). En s'appuyant sur [remark.js](https://remarkjs.com), [**knitr**](https://yihui.org/knitr), et [R Markdown](https://rmarkdown.rstudio.com). <a rel="license" href="https://creativecommons.org/licenses/by-sa/4.0/deed.fr"><img alt="Licence Creative Commons" style="border-width:0" src="https://i.creativecommons.org/l/by-sa/4.0/88x31.png" /></a><br />Ce(tte) œuvre est mise à disposition selon les termes de la <a rel="license" href="https://creativecommons.org/licenses/by-sa/4.0/deed.fr">Licence Creative Commons Attribution - Partage dans les Mêmes Conditions 4.0 International</a>.