class: title-slide, inverse .pull-left[ # Graphiques descriptifs ## ### Facundo Muñoz<br/>facundo.munoz@cirad.fr<br/>  ] .pull-right[  .credit[[Wikimedia commons](https://commons.wikimedia.org/wiki/File:Standard_deviation_diagram.svg#/media/File:Standard_deviation_diagram.svg)] ] ??? Nous allons explorer et comprendre les graphiques descriptifs plus habituels, selon le type de variable. --- layout: true <a class="footer-link" href="https://umr-astre.pages.mia.inra.fr/training/notions_stats/">Notions de base en statistiques - umr-astre.pages.mia.inra.fr/training/notions_stats/</a> --- # L'histogramme .pull-left[ - Variables __continues__ - Simple et __efficace__ - Estimation de la __densité__ ] .pull-right[ 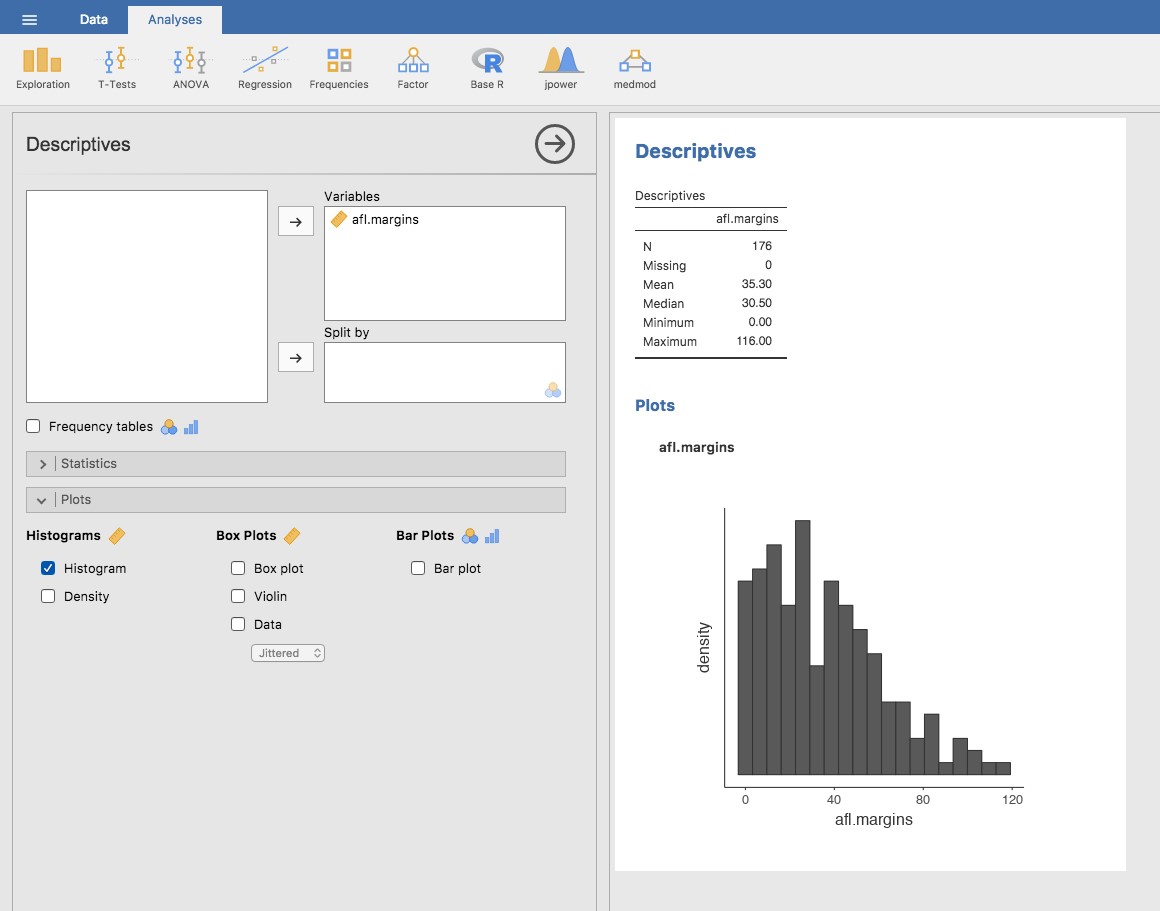 ] ??? Nous l'avons déjà introduit dans la séquence passée. - Notez qu'il n'y a pas des valeurs dans l'axe Y. Pour quoi ? - On ne peut pas contrôler le nombre d'intervalles. Limitation de Jamovi. - Cochez __densité__. Quelle information nous apporte ? - C'est le graphique par excellence pour décrire une __variable continue__ --- # Boxplots (boîte à moustaches) .pull-left[ - Variables __continues__ - Version plus __compacte__ de la répartition - __Médiane__ + __écart interquartile__ + __étendue__ - Identification (arbitraire) de __valeurs aberrantes__ ] .pull-right[ 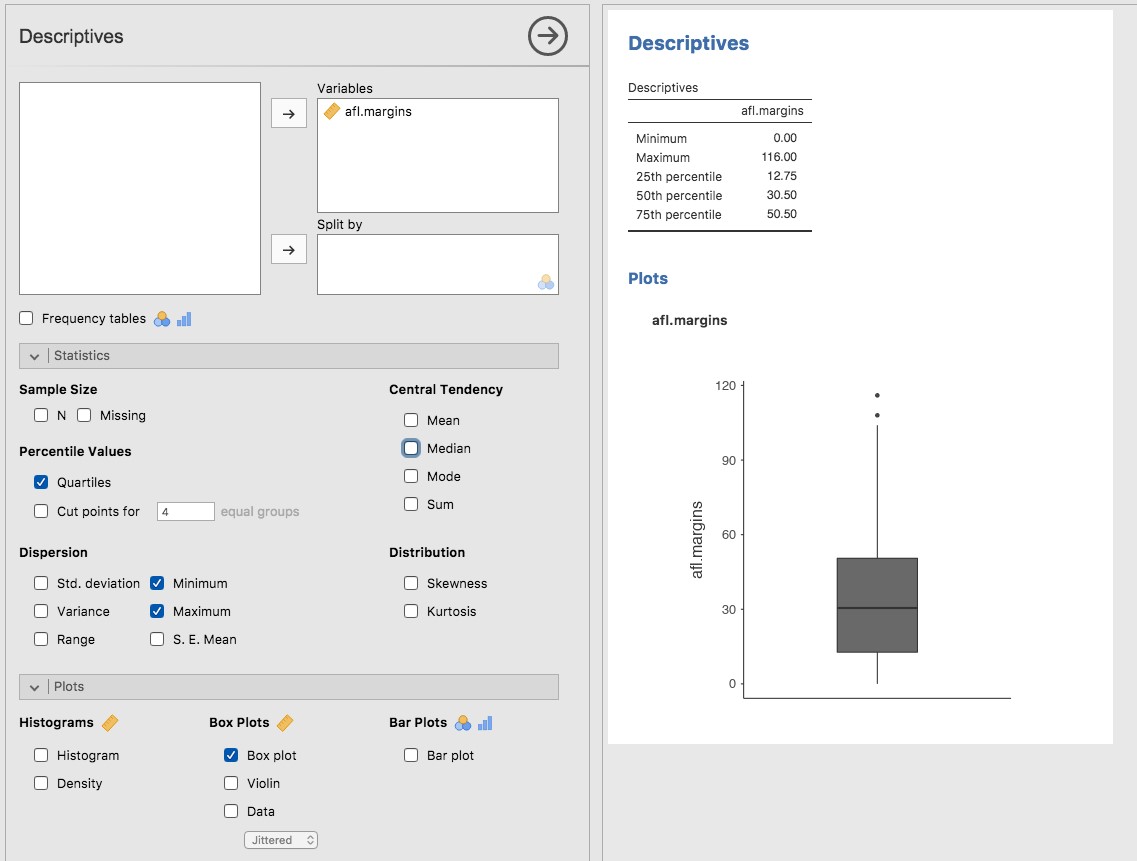 ] ??? Afficher les distributions de plusieurs variables au même temps, distribuées de façon régulière (i.e. unimodales) Les moustaches s'étendent jusqu'à `\(Q_1 - 1.5*IQR\)` et `\(Q_3 + 1.5*IQR\)`. C'est juste une limite arbitraire sans signification particulière. Mais peut être utile pour détecter des erreurs, et pour la modélisation (on verra plus tard) où on va utiliser certaines hypothèses sur les distributions des variables (e.g. normalité) - Essayez les options __violin__ et __data__. Qu'est-ce que cela vous apporte ? --- # Boxplots : point d'attention Comme pour les statistiques sommaires, résumer les données entraîne des dangers :  .credit[[Justin Matejka, George Fitzmaurice ](https://www.autodesk.com/research/publications/same-stats-different-graphs)] --- # Boxplots : point d'attention Les violin plots peuvent être un bon compromis :  .credit[[Justin Matejka, George Fitzmaurice ](https://www.autodesk.com/research/publications/same-stats-different-graphs)] ??? Ça vaut pas dire que les boxplots ne sont jamais appropriés. Juste qu'il faut vérifier qu'ils ne cachent pas de l'information __importante__ sur la répartition des données. --- # Exercice # Boxplots multiples 1. Chargez le jeu de données `AFL Margins By Year` dans __jamovi__ 2. Représentez la variabilité des marges __pour chaque année__ en utilisant des __histogrammes__ ??? Le jeu de données `AFL Margins By Year` contient les marges AFL non seulement pour 2010 mais pour chaque année entre 1987 et 2010. --- # Diagramme en barres (barplot) .pull-left[ - Variables __qualitatives__ - Ne pas __confondre__ avec l'histogramme - __Fréquence__ de chaque modalité .quote[Représenter la fréquence des équipes finalistes _Brisbane_, _Carlton_, _Fremantle_ et _Richmond_. Données `AFL Finalists`] ] .pull-right[ 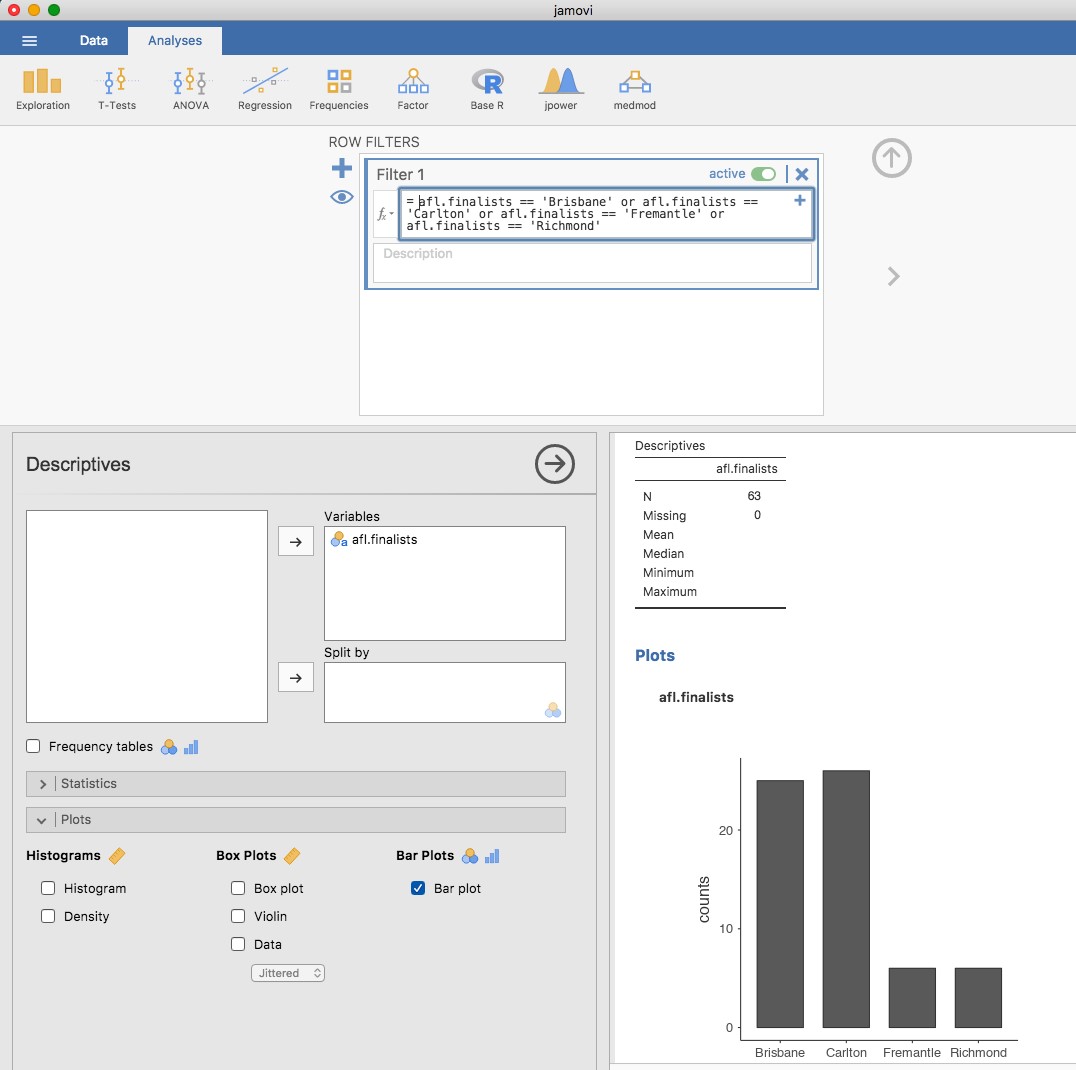 ] ??? Données AFL Finalists (équipes finalistes) Profiter de l'occasion pour introduire le filtre de données `afl.finalists == 'Brisbane' or afl.finalists == 'Carlton' or afl.finalists == 'Fremantle' or afl.finalists == 'Richmond'` Noter l'utilisation de `==` pour comparer deux valeurs. --- # Camemberts (pie charts) .pull-left[ - Variables __qualitatives__ - Parties d'un totale - ~~Très~~ trop populaires et abusés - Les __Barplots__ sont généralement à privilégier - Effectifs pour [certaines situations](http://speakingppt.com/why-tufte-is-flat-out-wrong-about-pie-charts/) ] .pull-right[  ] ??? Sauf quelques exemples très spécifiques, les humains avons du mal à comparer des angles. Il y a quelques cas d'utilisation qui restent valides. Je vous laisse un lien. --- # Relation entre variables La description des variables individuellement est importante .left-column[ - Heures de __sommeil__ du bébé et du papa, __irritabilité__ du papa - Données `Parenthood` de __jamovi__ ] .right-column[ <img src="S5.1_graphiques_files/figure-html/unnamed-chunk-1-1.png" width="90%" /> ] ??? Un nouveau père à enregistré les heures de sommeil de son bébé, les siennes et une mesure de son irritabilité (_grumpiness_) --- # Diagrammes de dispersion (scatterplots) ... mais les choses deviennent intéressantes quand on regarde la __variation conjointe__ des variables. .left-column[ - __Corrélation__ négative - Plus forte à __droite__ - Vous les estimez à combien ? ] .right-column[ <img src="S5.1_graphiques_files/figure-html/unnamed-chunk-2-1.png" width="90%" /> ] ??? C'est claire que __qualitativement__ on peut dire que plus de sommeil est associé à moins d'irritabilité, tant pour le sommeil du bébé que du papa. Mais __quantitativement__ on peut dire que la relation entre le sommeil du papa et son irritabilité est plus __forte__, plus __nette__. Si on vouliez prédire l'humour du papa, les heures de sommeil du bébé nous apportent une piste, mais c'est encore __plus utile__ de savoir combien d'heures a dormi le papa. Corrélations : -0.6, -0.9 --- # Corrélations et scatterplots dans __jamovi__ .left-column[ - _Regression_ > _Correlation matrix_ - Sélectionnez les trois __variables__ d'intérêt - Type __continue__. ] .right-column[  ] ??? - On reparlera un peu plus tard des autres coéfficients (Spearman et Kandall). Ils s'appellent des corrélations de rang : considèrent juste l'ordre, mais pas la magnitude. À peu près comme le coefficient de Spearman pour les rangs des observations. (e.g. classification de valeurs génétiques). - On reparlera aussi sur les p-valeurs. Essentiellement ils essayent d'apporter une mesure de __compatibilité__ des données avec l'hypothèse que les variables sont un échantillon de trois distributions normales indépendantes (ce qui est un peu absurde comme hypothèse). --- # Jeu : trouver la corrélation ## développez une intuition pour la magnitude des corrélations <iframe class="interactive" width="960px" height="380" scrolling="no" frameborder="no" src="https://tinystats.shinyapps.io/Guess_corr/"> </iframe> .credit[[Teacups, giraffes and statistics](https://tinystats.github.io/teacups-giraffes-and-statistics/index.html)] --- # Références - Stephanie J. Spielman [Common types of data visualizations](https://rowanbiosci.shinyapps.io/types_of_plots/). Application intéractive en ligne. - Claus O. Wilke [Fundamentals of Data Visualization](https://clauswilke.com/dataviz/). Livre en ligne. - [From Data to Viz](https://www.data-to-viz.com/). Guide en ligne pour choisir une visualisation adaptée aux type de données. - [Chapitre sur les principes de la visualisation de données](https://rafalab.github.io/dsbook/data-visualization-principles.html) (en anglais), chez [_Introduction to Data Science: Data Analysis and Prediction Algorithms with R_](https://rafalab.github.io/dsbook/). Rafael A. Irizarry. --- class: middle # Merci! Diapositives créées à l'aide du package R [**xaringan**](https://github.com/yihui/xaringan). En s'appuyant sur [remark.js](https://remarkjs.com), [**knitr**](https://yihui.org/knitr), et [R Markdown](https://rmarkdown.rstudio.com). <a rel="license" href="https://creativecommons.org/licenses/by-sa/4.0/deed.fr"><img alt="Licence Creative Commons" style="border-width:0" src="https://i.creativecommons.org/l/by-sa/4.0/88x31.png" /></a><br />Ce(tte) œuvre est mise à disposition selon les termes de la <a rel="license" href="https://creativecommons.org/licenses/by-sa/4.0/deed.fr">Licence Creative Commons Attribution - Partage dans les Mêmes Conditions 4.0 International</a>.